Data linking in Citehound¶
Data Linking refers to “the task of finding records in a data set that refer to the same entity across different data sources” [1].
Within the context of Citehound, data linking is used to relate (for example) a bibliographic data source’s affiliation information with the Research Orgnanisation Registry (previously GRID) [2] entities. Specifically, taking Pubmed as an example of a bibliographic data source, data linking would attempt to connect an author’s affiliation (e.g. an institute) with its ROR/GRID identity.
Entities are linked on the basis of string attributes, making the whole data linking process re-usable. In fact, linking in Citehound proceeds in two stages: First link any mention of a country name in an affiliation to the actual country and then link the institutes within that country.
This process is handled in a straightforward manner with only a few specific optimisations inserted by Citehound.
Overview of data linking¶
The general framework of data linking is as follows:
Given two sets of entities \(U,V\) we are trying to establish some relationship \(e(u,v)\) between two entities \(u_m,v_n\) on the basis of some expression of similarity \(g(u_m,v_n)\).
In set builder notation, establishing these relationships is expressed as:
\(E = \{(u,v) | u \in U, v \in V, g(u,v) \ge Th\}\)
Where \(Th\) is a threshold value (\(Th \in \mathbb{R}\)) that is used to convert “soft values” returned by the metric \(g\), into “hard decisions” (i.e. within the interval \(\{0 .. 1\}\).
This definition covers both types of linking, deterministic and probabilistic and hides away their conceptual differences.
This straightforward definition covers a “one-to-one” relationship between one element (\(u_m\)) of \(U\) to one element (\(v_n\)) of \(V\).
In Citehound we also had to consider the “one-to-many” relationship where it is necessary to link one element (\(u_m\)) of \(U\) to many elements (\(v_1,v_2,v_3, \ldots\)) and consequently establish more than one relationships.
In Citehound, “entities” are always strings, but where these strings come from is entirely up to the user, making the whole data linking process re-usable.
Linking matching string values (one-to-many)¶
One of the first data linkage processes that was implemented in Citehound was that of matching two sets of strings.
It was implemented first because it addressed one of our use cases directly. We had to match the country and institute names that appeared in the affiliation field with those provided by GRID.
An affiliation string is a “very wild animal”.
Here are only some of the forms it can be encountered in:
Address correspondence to Hannah Zeilig, BA, LCF, University of the Arts, London, 20 John Prince's Street, London W1G 0BJ, UK. E-mail: Hannah.Zeilig@kcl.ac.uk.Authors' affiliations are listed at the end of the article*Division of Brain Sciences, Imperial College London, London, United Kingdom; and Division of Metabolic and Vascular Health, Warwick Medical School, University of Warwick, Coventry, United Kingdom m.sastre@imperial.ac.uk.1] Institute of Psychiatry, King's College London, London, UK. [2].From the Clinical Trial Service Unit and Epidemiological Studies Unit, University of Oxford, Oxford, United Kingdom (R Clarke, DB, SP, SL, JA, JH, and R Collins); the Department of Human Nutrition, University of Otago, Dunedin, New Zealand (MS); the Section for Pharmacology and Department of Public Health and Primary Care, University of Bergen, Bergen, Norway (SJPME); the Department of Epidemiology, School for Public Health and Primary Care, CAPHRI, Maastricht University Medical Centre, Maastricht, Netherlands (SJPME); the Section of Hematology and Coagulation, Department of Internal Medicine, Institute of Medicine, Sahlgrenska Academy at the University of Gothenburg, Gothenburg, Sweden (CL); the Division of Cardiovascular and Medical Science, University of Glasgow, Glasgow, United Kingdom (DJS); the School of Medicine and Pharmacology, The University of Western Australia, Perth, Australia (GJH); the Population Health Research Institute and Department of Medicine, McMaster University, Hamilton, Canada (EL); the Department of Neurology, Western University, London, Canada (JDS); Unité de Recherche en Epidémiologie Nutritonnelle (UREN), Sorbonne-Paris-Cité, UMR Inserm U557, France (PG); Inra U1125, Paris, France (PG); Cnam, Paris, France (PG); Université Paris 13, CRNH IdF, Bobigny, France (PG); the Division of Human Nutrition and Epidemiology, Wageningen University, Wageningen, Netherlands (LCdG); the Department of Nutrition and Public Health Intervention Research, London School of Hygiene and Tropical Medicine, London, United Kingdom (ADD); and the Channing Division of Network Medicine, Department of Medicine, Brigham and Women's Hospital, Boston, MA (FG).
These strings have to be matched against much more strictly organised and clear lists of universities and countries.
This was addressed by establishing a one-to-many (\(1:*\)) process with clear semantics.
Following the notation established earlier, it is a function \(g_1(U,V, relationshipLabel, sessionID, percRetain, cutOff)\)
Where:
\(relationshipLabel\) is a label that is attached to a given relationship (\(e\)) and can be used to characterise it
\(sessionID\) is a label that is attached to a given relationship (\(e\)) and denotes the matching process that established it
\(percRetain \in 0..1\) is a threshold that trims the comparison sets (please see below)
\(cutOff \in 0..1\) is a threshold with semantics that are exactly the same as \(Th\).
\(g_1\) is non-commutative and the side-effects of \(g_1(U,V)\) (the intended) are different from the side-effects of \(g_1(V,U)\). This means that the order by which you pass parameters to \(g_1()\) matters.
This is because \(g_1\) incorporates:
A proportional filtering step over \(U\)
An iteration over the remaining elements of :math:’U’
A tokenisation of a given \(u\)
A “fuzzy” matching step between a given \(u\) and \(V\) before establishing one \(e=(u,v_n), n \in \mathbb{N}\)
Proportional filtering¶
Proportional filtering is based on the observation that the lengths of strings coming from natural language will follow a non-uniform distribution [3]
For example, the majority of country names have between 4 and 9 letters in their names and very few of them extend all the way up to 30
characters(fig 1). Examples of the longest country names are Democratic Republic of the Congo, Saint Vincent and the Grenadines.
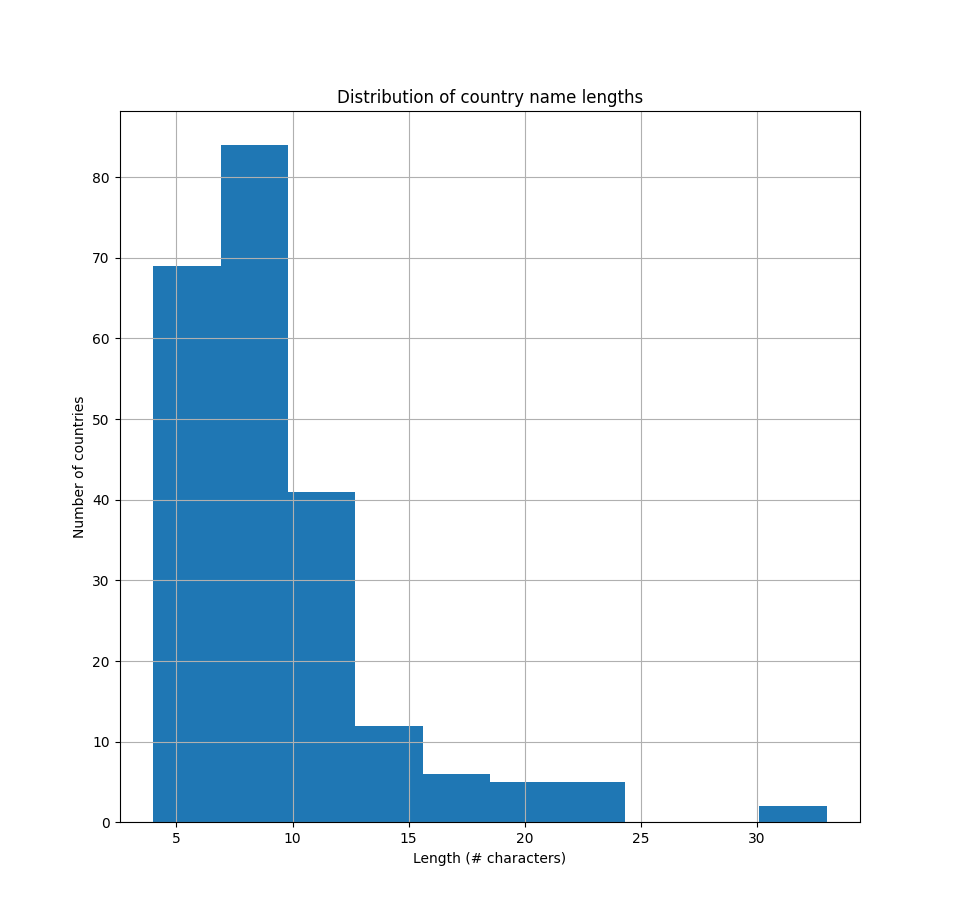
Fig. 4 Distribution of country name lengths, using the countries referenced by ROR.¶
Consequently, the tokenisation of a given affiliation \(u_m\) might produce items that are far longer than 4 to 9 characters of the majority of country names.
There is absolutely no reason to burden the evaluation of string similarity with comparison of strings that we know are 9 characters long with strings that we know that are 30 characters long.
Proportional filtering applies a filter on elements of \(U, V\) that takes into account their distribution of lengths to try and exclude impossible matches that are known to be poor matches in advance.
Since we are aiming to establish one-to-many relationships, proportional filtering drastically reduces the total ammount of comparisons / operations that would need to be applied per entry.
“Blocking” and final linking¶
Citehound’s low level generic data linking explained above is applied in two stages on two pairs of entities to produce the final “linking”.
At the first stage: Any mention of a country in an author’s affiliation is linked to the corresponding Country entity of the ROR dataset.
This information is then exploited to reduce the complexity of the second stage.
Instead of trying to match a given random affiliation sub-string with all the known institutes in the ROR dataset, apply “blocking” by country and compare it only to the subset of institutes within the given country. This is further reduced by proportional filtering on institute names of course.
